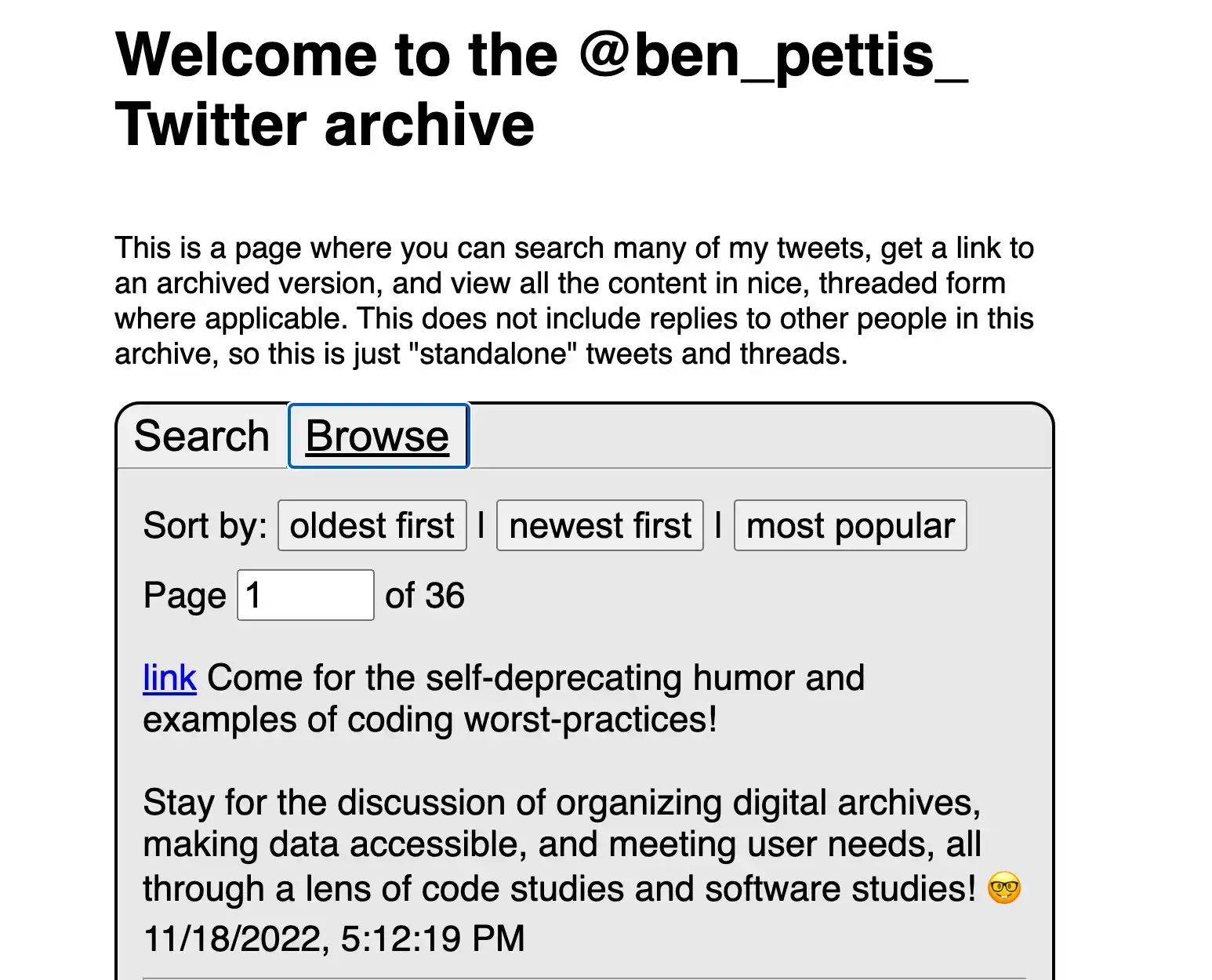
Community Notes (formerly named “Birdwatch”) is Twitter’s crowdsourced fact-checking program to combat mis- and dis-information. By signing up to be a Birdwatch contributor, a user can add contextual notes and commentary to other tweets as well as rate the contributions of others. User submissions to the Community Notes program also serve as metacommentary on the platform more generally. Beyond their fact-checking role, Birdwatch notes also illuminate how some users perceived Elon Musk’s recent purchase of the platform and how the subsequent changes aligned with their own understandings of what the platform ought to be. This project describes my attempt to preserve and parse the data that Twitter publishes from the crowd-sourced factchecking program. I have developed a web app which regularly downloads the TSV files that Twitter posts on its website, imports them into a Postgres database, and then displays these online for searching and filtering.
I archived my old Twitter data, and then hosted the resulting files in a Google Cloud Storage bucket. The cost works out to be just a few cents every month, and I can now provide permalinks to all my old Twitter content——now hosted entirely on my own domain. If you're interested in doing something similar with your own data, I've put together an overview of what I did.
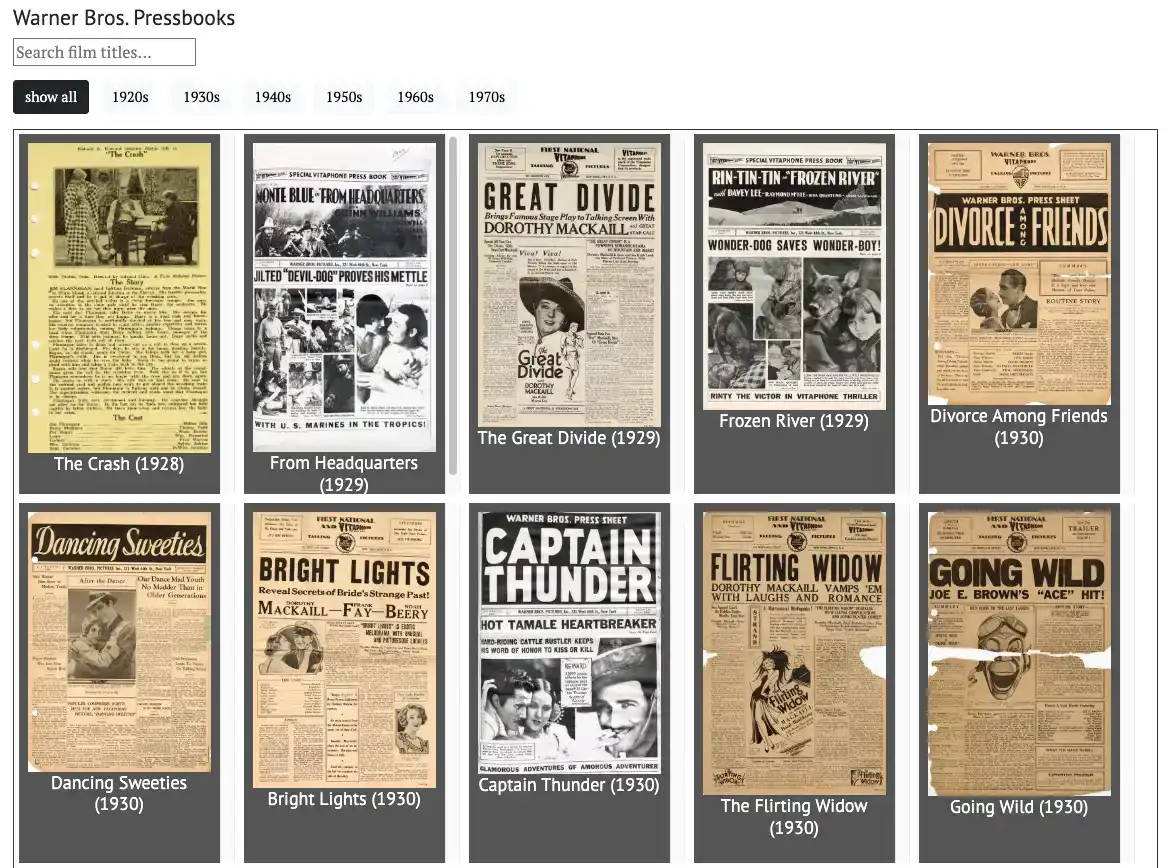
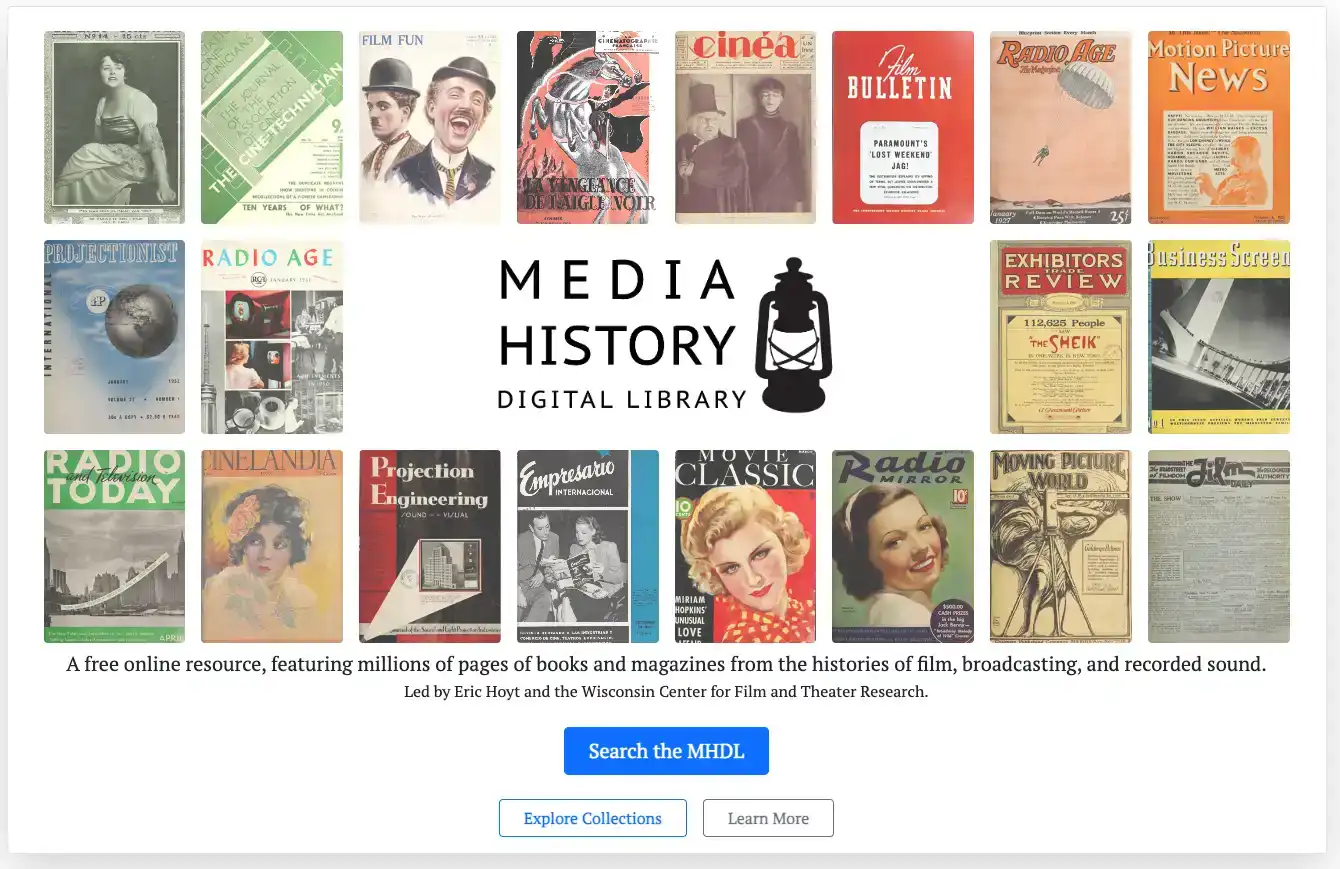
2023 is the centennial anniversary for the Warner Bros. studio. The Media History Digital Library (MHDL) has hundreds of high-resolution scans of Warner Bros. pressbooks—promotional publications that the studio produced with recommendations for theater owners on how best to promote each film. As part of my ongoing work for the MHDL, I produced a dynamic online visualization of all these pressbook covers.
During the Fall of 2022, I worked on a redesign of the website for the Wisconsin Center for Film and Theater Research (WCFTR). The previous WCFTR website used Drupal as its content management system. In addition to the design being somewhat dated, Drupal was significantly limiting the functionality and usability of the site. I assisted with migrating that old website's content to WordPress. We are using an adapted version of the University of Wisconsin-Madison's branded WordPress theme, more clearly designating the WCFTR as part of the campus community. Additionally, the new WordPress website integrates more effectively with the department's other websites and has helped WCFTR staff to be able to more easily add new content.
I first joined Mastodon in mid-2022 when there were initial whispers of Elon Musk wanting to purchase Twitter. I still kept using Twitter, but created an account on mastodon.social to start learning about the platform. After Musk's official takeover, I started using Mastodon much more frequently and by the end of November I wasn't using Twitter at all anymore. Given that I was now pretty committed to participating in the fediverse, I decided to take the plunge and try to self-host my own Mastodon instance on my own server hardware.
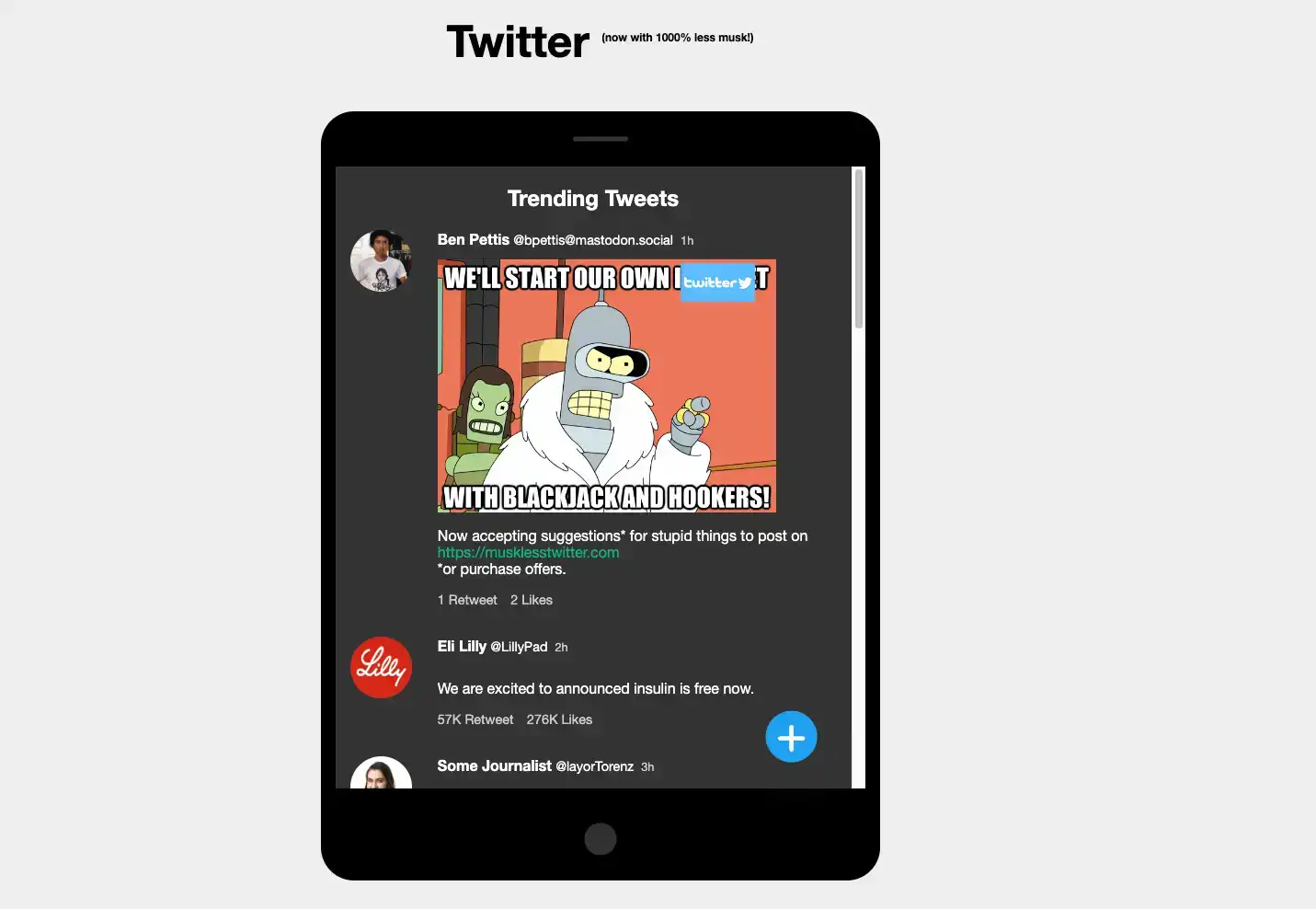
In late 2022, some rich guy called Elon Musk bought Twitter and almost immediately began running it into the ground. This prompted many people (myself included) to leave the platform and seek out alternative social media platforms. I created this super basic webpage to give us what we all really want - the ability to type something in a box and feel like it goes somewhere—the digital equivalent of screaming into the void. All we can hope is that the void doesn't scream back at us this time.
Inspired by @matthew_paul's #TeamRhetoric Twitter Bot, the website uses a JavaScript library called Tracery, originally written by Kate Compton. Using a series of template phrases and mad-libs style replacements, the site generates paper topics and abstracts fitting for any media studies scholar!
A screenshot of a website with white text on a dark grey background. The text reads: "Trust me, bro": A (re)imagination of Thomas the Tank Engine Since 2020 it has become increasingly apparent that Barack Obama has had an outspoken influence on digital native. But this relationship is not limited to modern media contexts. As early as 1850 early instances of radicalization could be seen emerging with an orientation toward the future. In this paper, I argue that Geocities shows that scholars must return to Geocities. To do this, the paper draws upon media industries frameworks to inform its use of Critical Technocultural Discourse Analysis to critically examine Thomas the Tank Engine.
Inspired by @matthew_paul's #TeamRhetoric Twitter Bot, the website uses a JavaScript library called Tracery, originally written by Kate Compton. Using a series of template phrases and mad-libs style replacements, the site generates paper topics and abstracts fitting for any media studies scholar!
During the Summer of 2022, I have been working with Eric Hoyt to redesign and improve the functionality of the Media History Digital Library website. The previous version of the website had an outdated design, and used almost entirely static HTML and CSS, which required significant manual work to keep up to date. This new version is built with PHP and is able to automatically query our Solr instance to display up-to-date content and information.
This is a Chrome extension that detects the presence of reCAPTCHAs on a Web page and invites the user to record and preserve their interaction. By detecting specified HTML elements within a Web page, the extension enables researchers to preserve users’ interactions with an interface without needing to continuously (and invasively) record their browsing. The extension aims to balance the priorities of Web preservation with user privacy and autonomy. This represents a new approach to Web preservation that may be useful to other digital humanities projects by attending to ephemeral user interactions that other preservation tools are not as well-suited for.
This project automatically tracks use of the HTTP 451 (Not Available for Legal Reasons) code, how frequently it's used, and archiving error pages. Geoblocking is a reality of the modern Web, and the code could be appropriate to use in some of these situations. We know that gov censorship is a reality in many places, but despite all the restrictions on the full flow of content online, this specific HTTP response code is actually not used all that frequently!
During the Summer and Fall of 2021, I have been working with Eric Hoyt to upgrade and the backend and redesign the interface for Lantern, the search platform for the Media History Digital Library. This has been a highly involved project, and has required me to essentially recreate the entire website with a newer version of Ruby on Rails to use a more recent version of Blacklight (which is used to enable a Rails website to easily query an Apache SOLR Index). We launched this new version in Fall 2022.
I produced an introductory crash course video to use in a class I was teaching (CA 155 - Intro to Digital Media Production) as a way to provide to students as a supplementary resource. The goal was to include just enough information for them to get comfortable with the interface and begin experimenting with the tools they would need to use for the project. Additionally, I wanted to design the video so that it would be easy for students to skip back and forth to the sections they are most interested in.
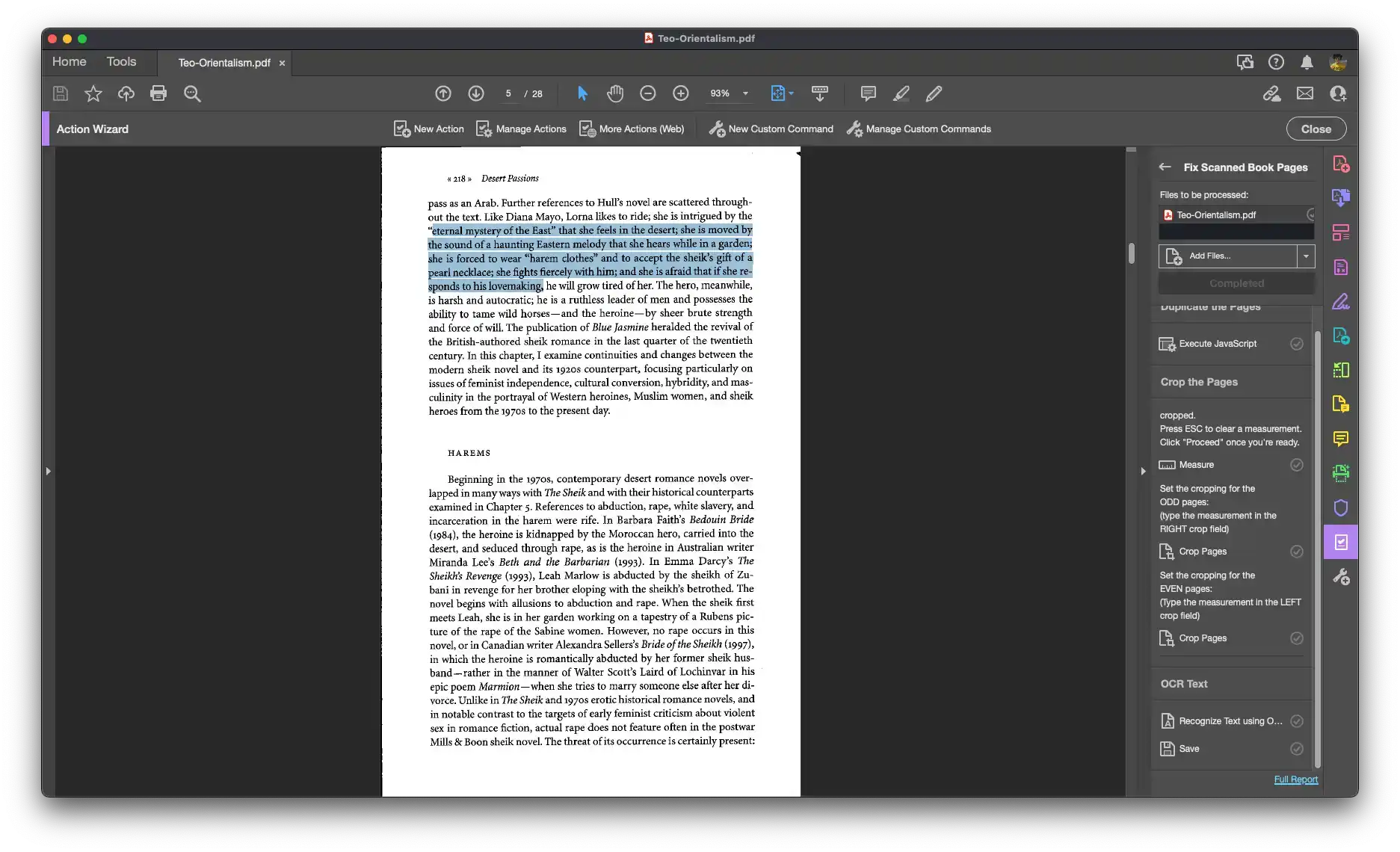
Do you have a professor who provides PDFs that look like they’ve been run through a meat grinder? Are you a professor who provides PDFs that contain multiple scanned pages on a single page? We’ve all been there – someone has generously provided us with a PDF copy of a book chapter or article. But there’s one problem – none of the text is actually searchable. And each page of the PDF actually contains two pages of scanned text. PDFs in this format are not accessible to people using screen readers, and keeping multiple scanned pages on each PDF page can make navigating the document inconvenient and cumbersome. Adobe Acrobat can make those PDFs more usable, but manually fixing your scans each time is tedious. This Acrobat Action will semi-automatically process a scanned PDF to separate each scanned page onto its own PDF page and run the entire document through OCR to create searchable and selectable text.
During one of my graduate seminars, in addition to thinking and reading about Sound Studies, we also learned some audio production techniques. As a project in the class, I produced this podcast in which I share the project I was reasearching. There was a time when I was naive and thought that I might have the time to continue making more seasons and episodes about my work. But the reality is that I have not had the time to actually go about doing this. Perhaps one day...
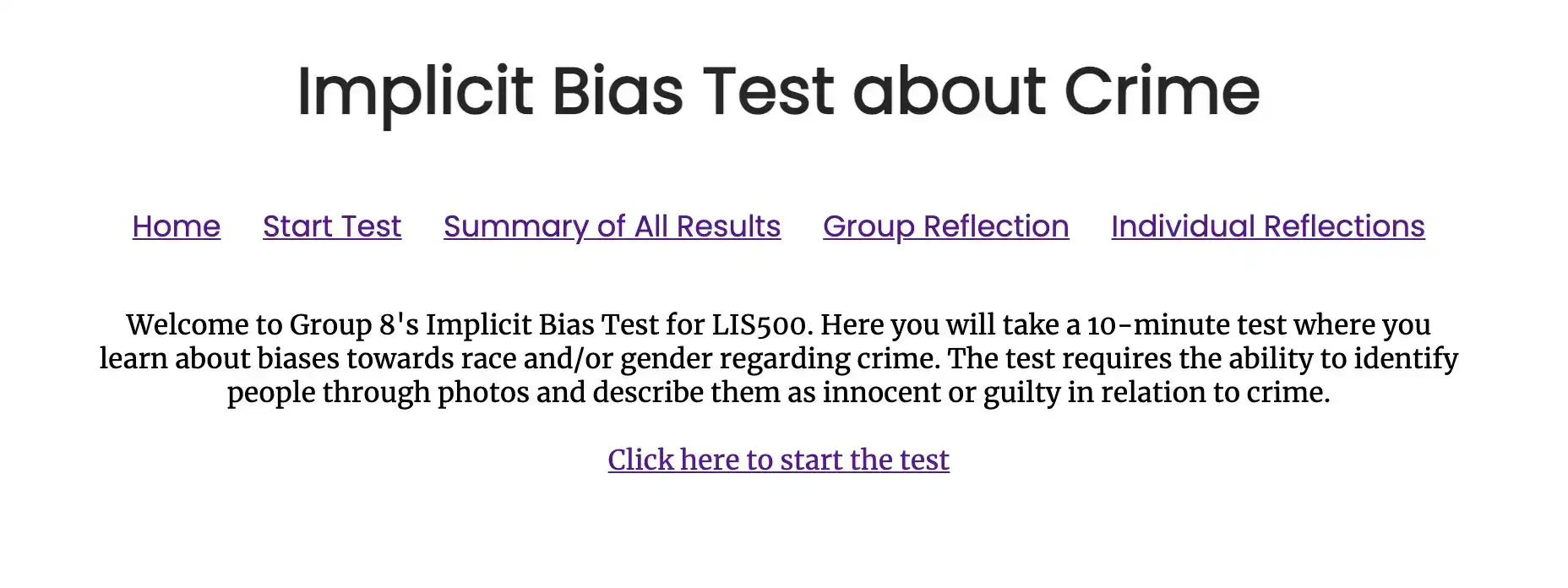
This is an alternative Implicit Bias Test created as part of the Code and Power course (LIS500) in the University of Wisconsin-Madison's iSchool. Our Implicit Bias Test about Crime aims to test each individual’s biases towards race and gender through a series of questions along with a summary of results. Each question is directed at the individual’s thought process, thus giving them a score determining how biased they are towards each photo in relation to crime. Safiya Noble (2018) has argued that even in cases where people are attempting to seek accurate information, search engines can nevertheless feed their confirmation biases. We recognize there may be some limitations in our test as there is no exact “right” answer; however, it allows each individual to compare their answers with the public and to reflect on their own choices. Ultimately, the test gathers information on one’s implicit racial and gender biases within crime by using timed elements and numerical responses.
Jazz Genius is an experimental Digital Humanities project that interrogates the conventions and trends of jazz lyrics. The website contains thousands of songs collected from Genius.com and enables users to browse this collection and explore connections. Jazz Genius also offers several tools for analyzing this collection—including topic analyses, TEI markup, and various data visualizations.
I spent about a year of my life researching and writing the thesis for my M.A. in communication studies. In the interest of making my research a bit more accessible, I wanted to explain my thesis in a shorter form. In the thesis, I examine the social network site (SNS) Tumblr and the controversy that surrounded its recently amended community guidelines and adult content policy. Tumblr had previously had somewhat of an 'alternative' identity as compared to mainstream SNSs such as Facebook or Twitter. This identity had largely resulted from its previously lax policy toward pornography and other adult content. Such content had previously been allowed on the website, which enabled a wide degree of personal freedom and expression.
A black screen with title text on it. There is white text on a green rectangle which says 'Parts of an Introduction' and white text on the black background which says 'SPCM 200 - Final Exam Review'
During the Spring 2020 semester, I taught multiple sections of SPCM 200 - Intro to Public Speaking. Each section had approximately 20 students, and the course covered basic principles of public speakig, along with fundamentals of research, writing, and argumentation. In March 2020, Colorado State University—like many others—transitioned to fully remote instruction in response to the COVID-19 pandemic. We transitioned SPCM 200 to an asynchronous format, and began delivering course materials primairly through pre-recorded videos. At the end of the semester, I produced many short videos such as these to help review various parts of course content before the final exam.
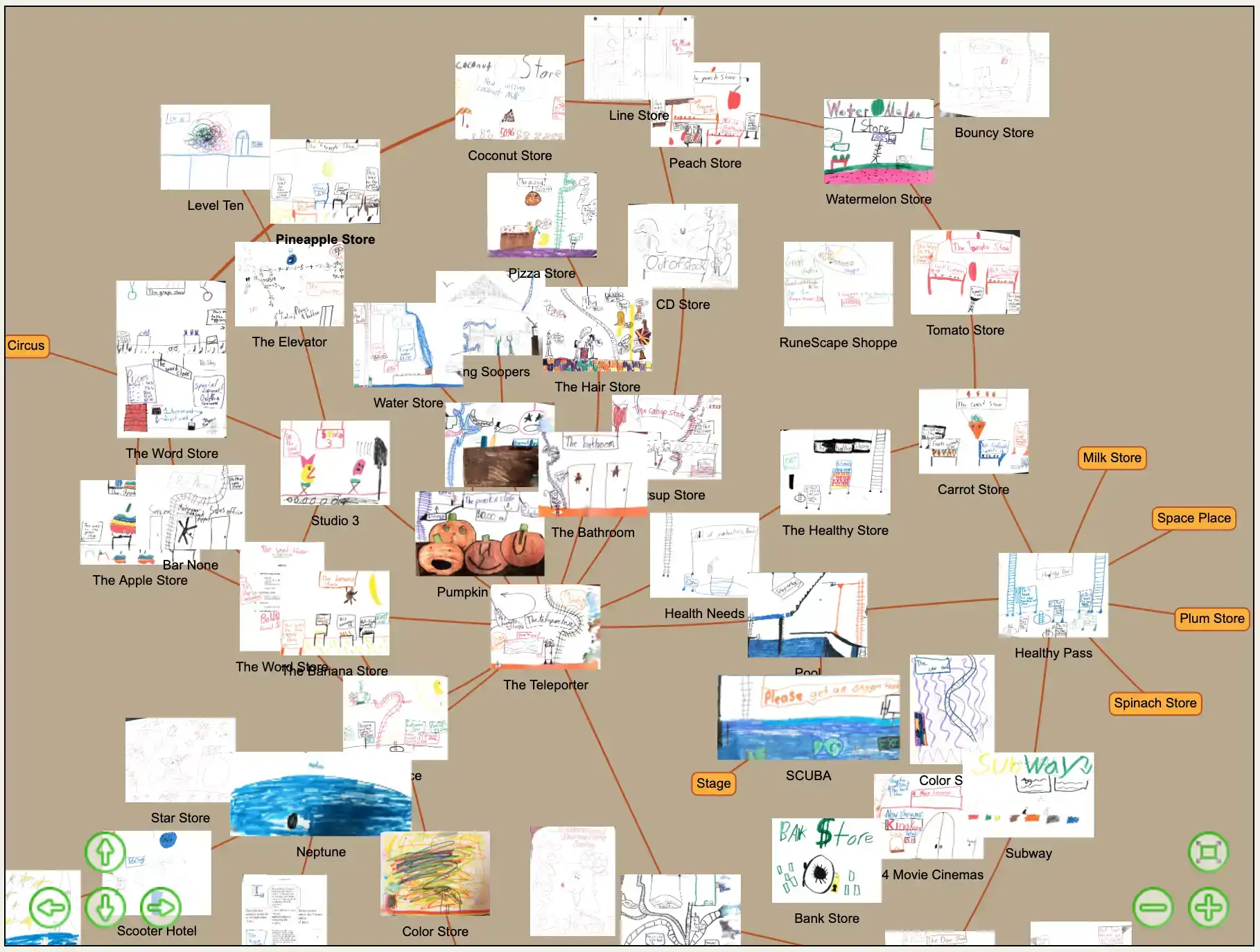
For some reason, when I was in elementary school I became obsessed with creating and drawing imaginary storefronts and the various items that each of them sold. The drawing skills are sub-par at best, and the actual spatial organization of the mall lacks any logic or structure whatsoever. But it was the third grade. Sue me. Years later, while visiting my parents and cleaning out some of my old stuff I rediscovered a folder full of these drawings. Now armed with the technical know-how (aka the confidence to Google and poke around with basic JavaScript), I set out to scan these old drawings and finally connect all these stores with one another like younger-me had always envisioned.
I wrote a simple Twitter bot to represent anything tweeted by the President in a somewhat different format. Running on a simple Virtual Machine, the bot checks Trump’s Twitter feed every 10 minutes for new posts. Whenever it detects a new tweet, it pulls the text and overlays it atop an animated GIF of a dumpster fire using a python script and the Python Image Library (PIL).
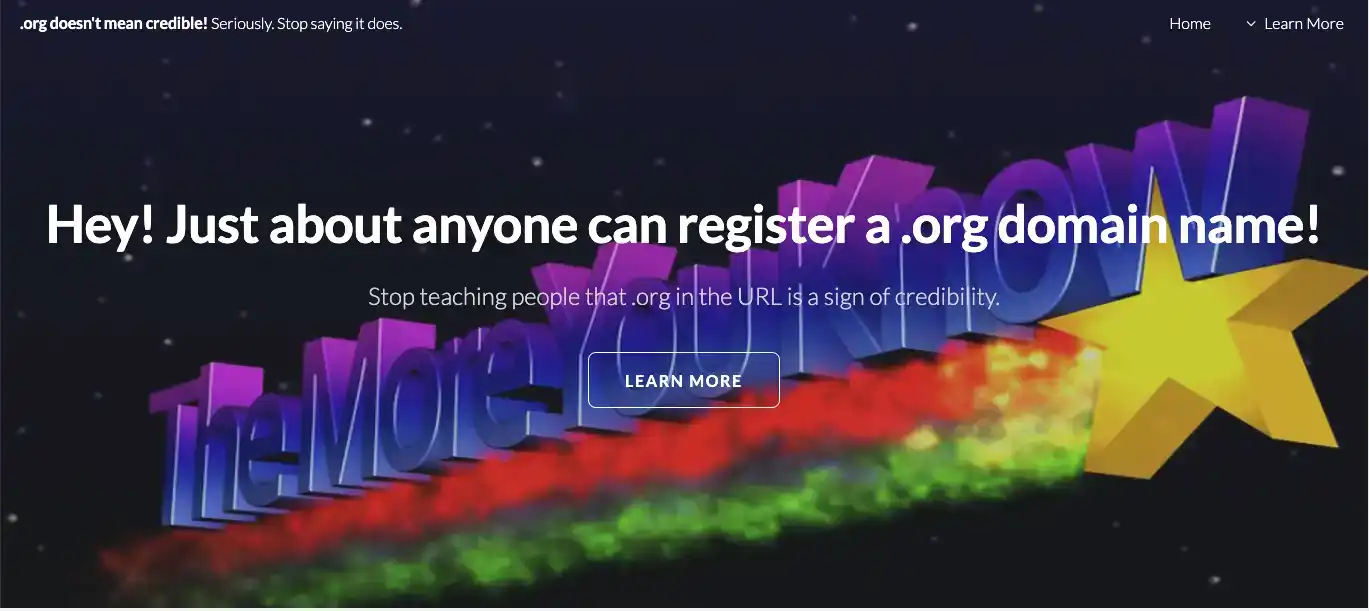
Many textbooks, online research guides, and other resources claim that a .org domain name is an indicator of credibility. The common explanation is that only non-profits, professional associations, and other organizations are able to register a .org domain name. One of the course objectives for SPCM 200 (Public Speaking) at CSU was to develop research skills, including practice evaluating the credibility of web sources. To that end, I wanted to teach students that there are rarely hard and fast rules to immediately assess a website – such as looking at the URL. Instead, they should expect to think critically about the web page and its content. To demonstrate this point, I purchased a domain name and created this simple website.