Other Projects
OtherJuly 06, 2023
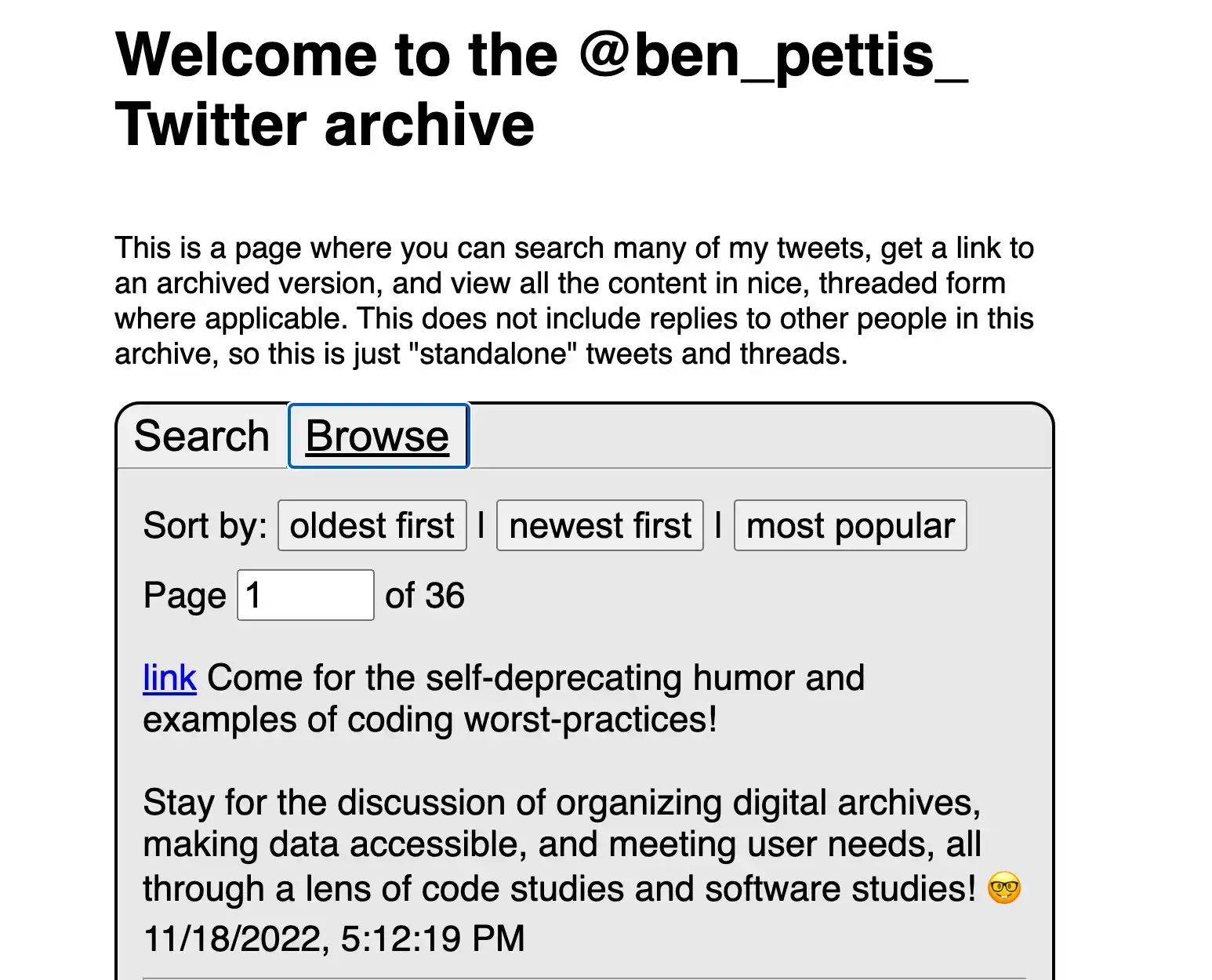
I archived my old Twitter data, and then hosted the resulting files in a Google Cloud Storage bucket. The cost works out to be just a few cents every month, and I can now provide permalinks to all my old Twitter content——now hosted entirely on my own domain. If you're interested in doing something similar with your own data, I've put together an overview of what I did.
Read More... OtherMay 20, 2022
This is a Chrome extension that detects the presence of reCAPTCHAs on a Web page and invites the user to record and preserve their interaction. By detecting specified HTML elements within a Web page, the extension enables researchers to preserve users’ interactions with an interface without needing to continuously (and invasively) record their browsing. The extension aims to balance the priorities of Web preservation with user privacy and autonomy. This represents a new approach to Web preservation that may be useful to other digital humanities projects by attending to ephemeral user interactions that other preservation tools are not as well-suited for.
Read More... OtherJanuary 01, 2022
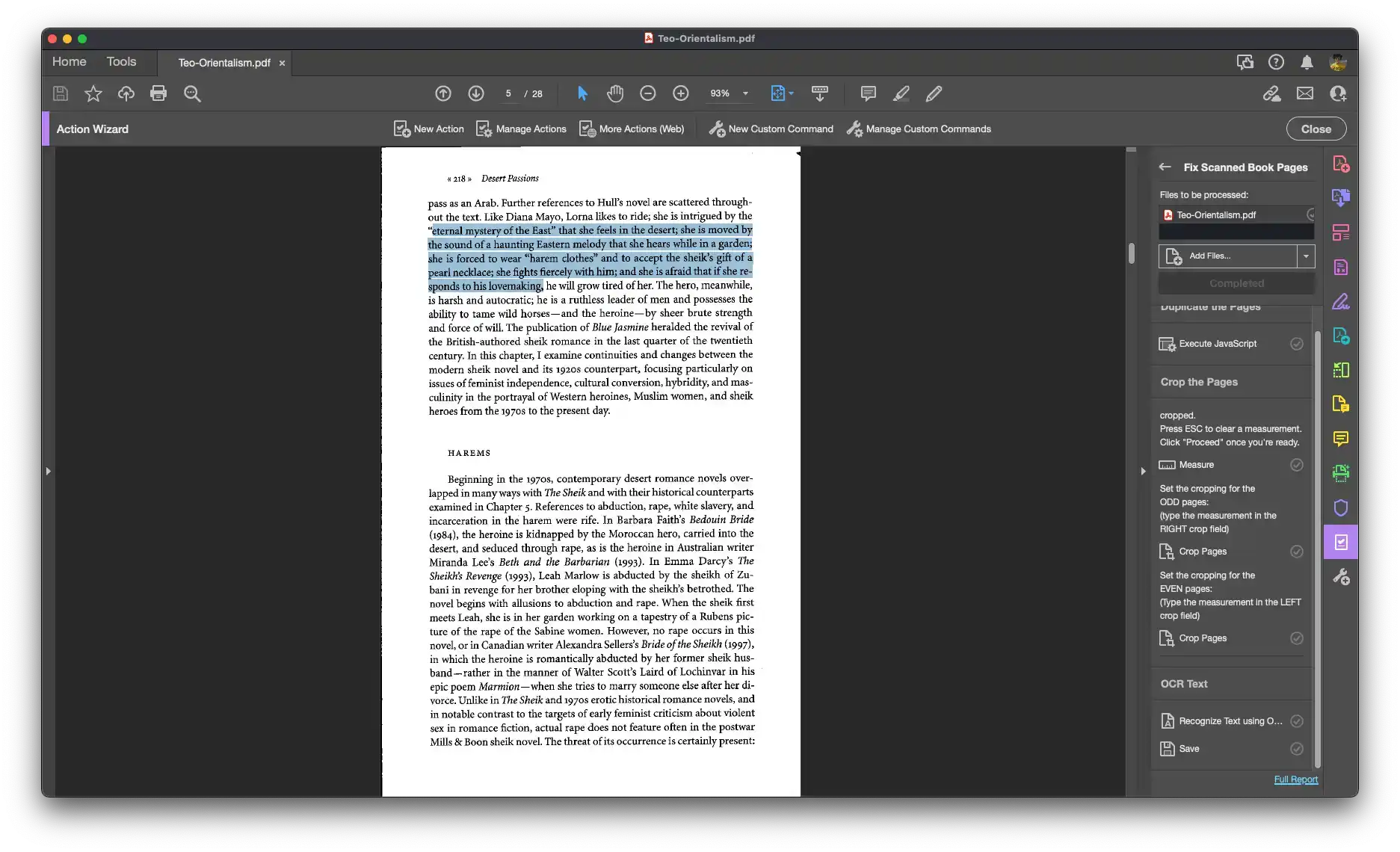
Do you have a professor who provides PDFs that look like they’ve been run through a meat grinder? Are you a professor who provides PDFs that contain multiple scanned pages on a single page? We’ve all been there – someone has generously provided us with a PDF copy of a book chapter or article. But there’s one problem – none of the text is actually searchable. And each page of the PDF actually contains two pages of scanned text. PDFs in this format are not accessible to people using screen readers, and keeping multiple scanned pages on each PDF page can make navigating the document inconvenient and cumbersome. Adobe Acrobat can make those PDFs more usable, but manually fixing your scans each time is tedious. This Acrobat Action will semi-automatically process a scanned PDF to separate each scanned page onto its own PDF page and run the entire document through OCR to create searchable and selectable text.
Read More... OtherNovember 01, 2021
During one of my graduate seminars, in addition to thinking and reading about Sound Studies, we also learned some audio production techniques. As a project in the class, I produced this podcast in which I share the project I was reasearching. There was a time when I was naive and thought that I might have the time to continue making more seasons and episodes about my work. But the reality is that I have not had the time to actually go about doing this. Perhaps one day...
Read More... OtherJanuary 01, 2020
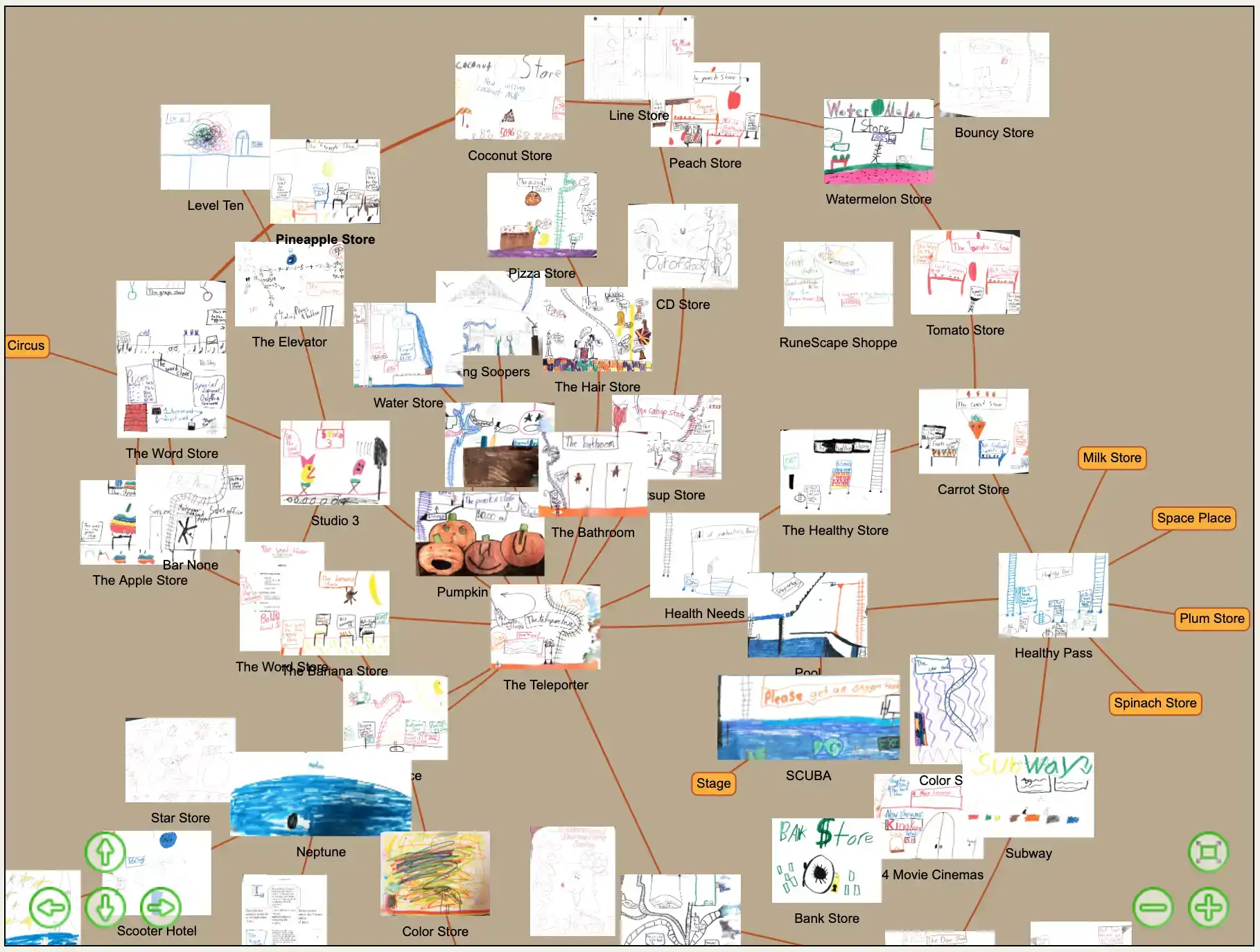
For some reason, when I was in elementary school I became obsessed with creating and drawing imaginary storefronts and the various items that each of them sold. The drawing skills are sub-par at best, and the actual spatial organization of the mall lacks any logic or structure whatsoever. But it was the third grade. Sue me. Years later, while visiting my parents and cleaning out some of my old stuff I rediscovered a folder full of these drawings. Now armed with the technical know-how (aka the confidence to Google and poke around with basic JavaScript), I set out to scan these old drawings and finally connect all these stores with one another like younger-me had always envisioned.
Read More... OtherJanuary 01, 2019
and downloading content from 4chan imageboards, I built this script to automatically scrape the most recent content from a given 4chan imageboard.
Read More...